Worm, authored by Wildbow (John C. McCrae), is a web serial of over 1.6 million words (with a vocabulary size of 20,416 words) across over 300 chapters. Having just finished reading it and its sequel, Ward, I chose to use it as a small toy corpus while experimenting with new NLP libraries.
In the plots used in the following analysis, I used the convention that more blue points indicate chapters closer to the beginning of Worm, while more red points indicate chapters closer to the end, allowing the visualization of trends over time.
All code for the following analysis is located here.
Doc2Vec
Doc2Vec is an enhancement of the Word2Vec model. Word2Vec creates vector models of a word by training a shallow neural network on a window of neighboring words around each occurrence of the word, resulting in a mapping from words to vectors. Doc2Vec models also train a document vector for each document in the corpus, which is treated as if it is neighboring every word in the document. Doc2Vec models outperform simple averaging of the Word2Vec vectors of the text of a document when used for tasks such as sentiment analysis. I used the Doc2Vec implementation from Gensim for this project.
Principal Component Analysis
Principal component analysis is the process by which the directions of greatest variance are computed for a set of input vectors, where such direction vectors (or “principal components”) form an orthonormal basis of the input space. The components are ordered such that the higher ranked principal components “capture” a larger portion of the variation in the dataset (i.e., the higher principal components point in the most prominent directions of variation in the input data). By forming a basis of only the top components, we can project the data onto these components to preserve the important variations in our dataset while removing noise or less important trends, using PCA as a method of dimensionality reduction.
In the following experiments, the default scikit-learn PCA implementation is used to visualize higher dimensional vectors, as we can isolate the top two principal components in a set of vectors and use these as a basis along which we can observe the most important trends in the data in a 2D plot.
Initial Experiment: Vector Size and PCA
In my initial analysis of this data, I decided to train Doc2Vec vectors of increasing dimension. I applied PCA to reduce the resulting vectors from each model into two-dimensional data for ease of visualization and observation of directions of variation. The other hyperparameters were left at the default values, with the notable exception of the training epoch count, which I increased to 40. Increasing the number of epochs was both suggested as a method of improving performance on smaller corpora by the Doc2Vec tutorial and beneficial to the stability of the training process across multiple runs.
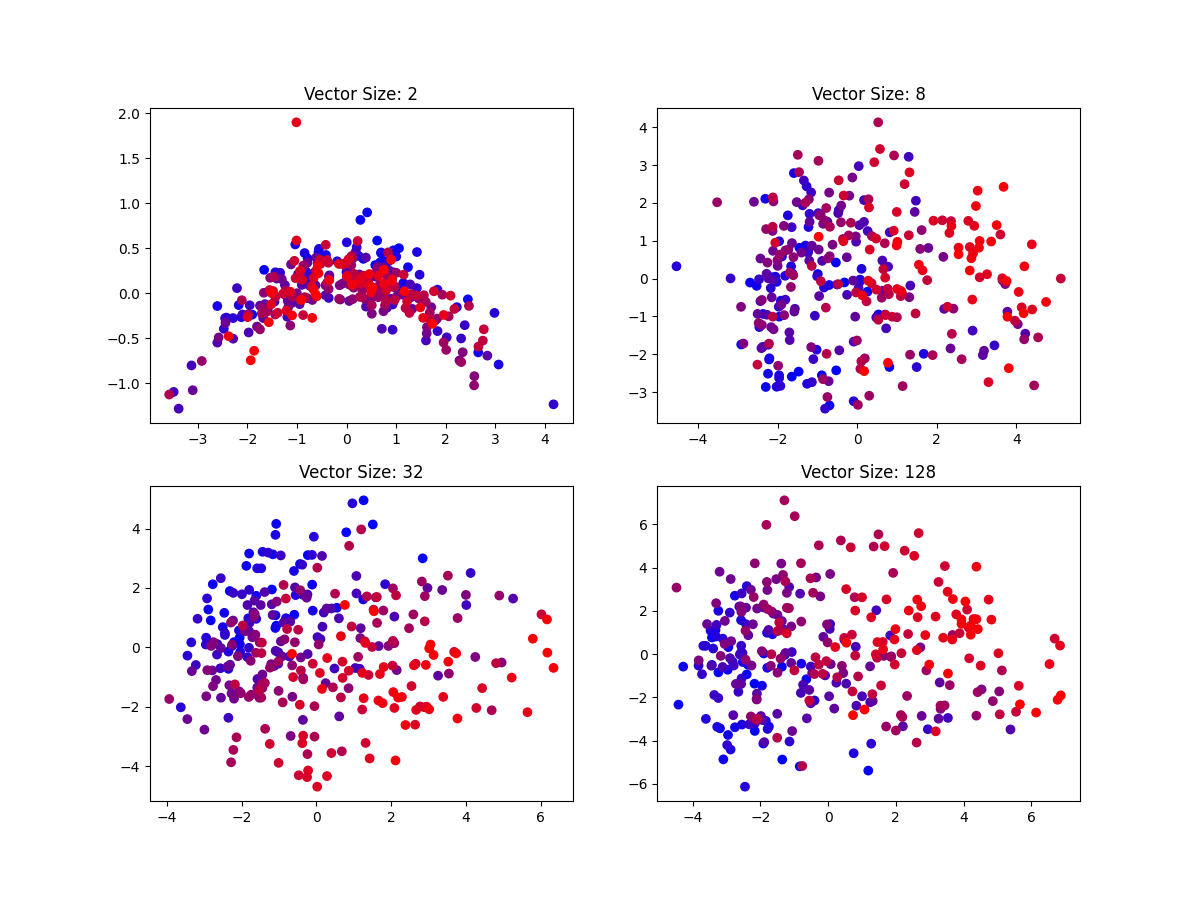
The plots for larger vector sizes demonstrate a clear pattern along the first principal component, where movement along the axis corresponds to moving from earlier to later chapters of the book. This could imply a strong semantic difference between content at the beginning and ends of the book, which is perhaps the expected result for such a long work that varies in scope as it progresses. We can also note that later chapters are less clustered, indicating more variation between the contents of individual chapters later in the work than earlier, though this is only truly evident in the plot for vector size 32.
A noticeable trend exhibited only in the plot for vectors with dimension 2 is the curve structure into which the majority of the data fall. Both ends of the curve exhibit tails of outliers, with one end having a particularly strong outlier, and one outlier exists apart from the curve structure entirely. The chapters corresponding to the two most egregious outliers are Interlude 27b (the red point outside of the curve structure entirely) and Tangle 6.4 (the blue point near one of the ends of the curve). The length of Interlude 27b is sufficient as an explanation for its outlier position, as the chapter length of 4 words makes it very sensitive to those words and the document being shorter than the window length may have introduced some complications in training. However, Tangle 6.4 does not appear significantly different from the rest of the chapters, and the cause of this outlier remains unclear.
As these outliers are much less extreme or disappear entirely with higher dimensional vectors, it is possible that there is no meaning to the Tangle 6.4 outlier, and this was simply a result of the vector size being too small to adequately represent the chapters. One way in which this is perhaps noticeable is the amount of overlap between blue (early chapters) and red (late chapters) points in the curve structure, compared to the separation exhibited in higher dimensions.
To evaluate other possible causes of this outlier, I returned to the use of a vector size of 2 and varied other hyperparameters.
Increasing the Minimum Count
One possible cause for this outlier is the existence of rare words whose representations skew the representation of the entire chapter. If such a word appears only a few times in the corpus, or even just once, as a hapax legomenon, its representation would be very skewed towards those words that appear in the contexts of its few occurrences, and consequently its representation may not be “reasonable” with respect to its meaning. Increasing the optional min count parameter excludes words that appear below a certain number of times in the corpus, preventing these words from influencing the representations of their documents and other words.
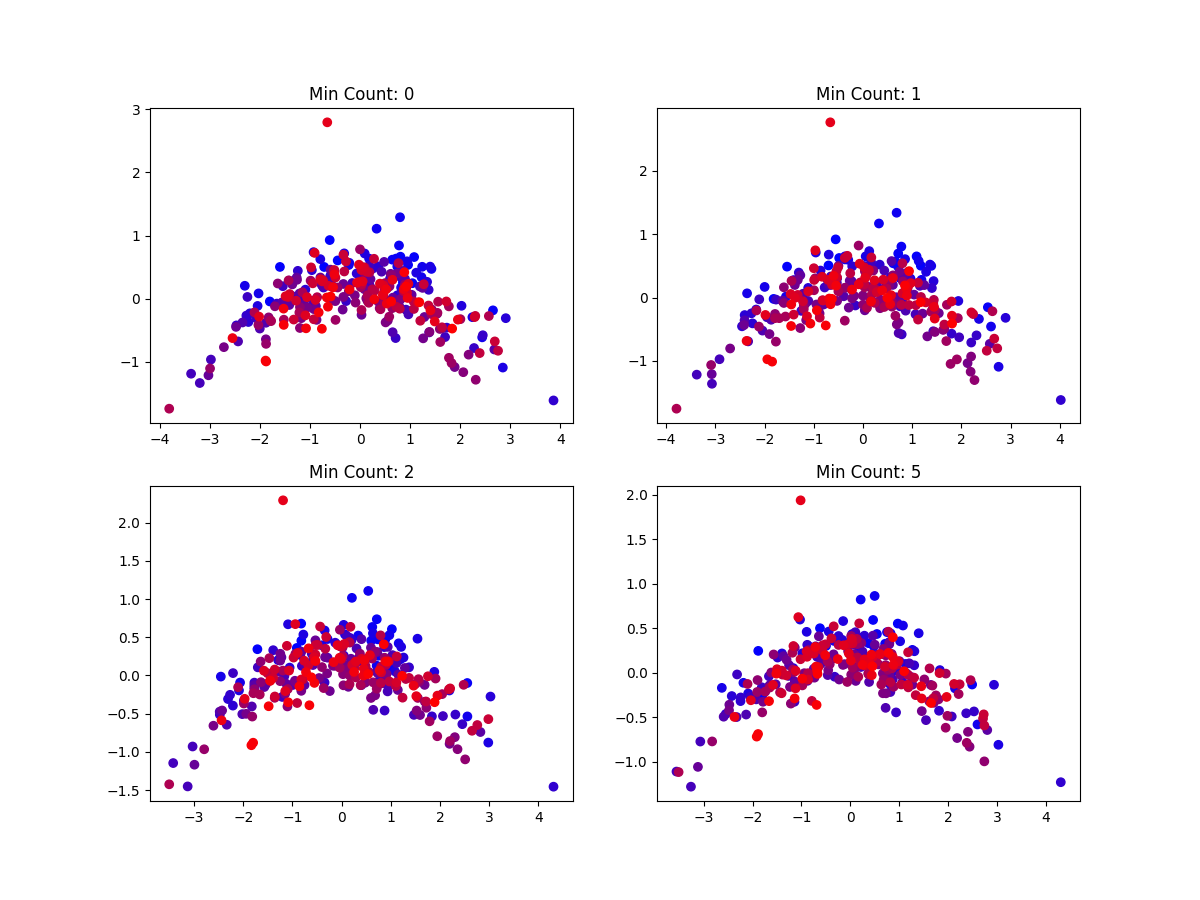
However, we see that the outlier continues to exist even with increased minimum count values, suggesting that the outlier’s presence is not due to the existence of rare words in the chapter.
Changing the Window Size
When applying Word2Vec and similar techniques, shorter window sizes are associated with learning representations modeling syntactic aspects of documents, while longer windows are associated with semantic similarities and differences. Thus, if the outlier only appears with short windows, it is likely due to some syntactic irregularity rather than a semantic difference.
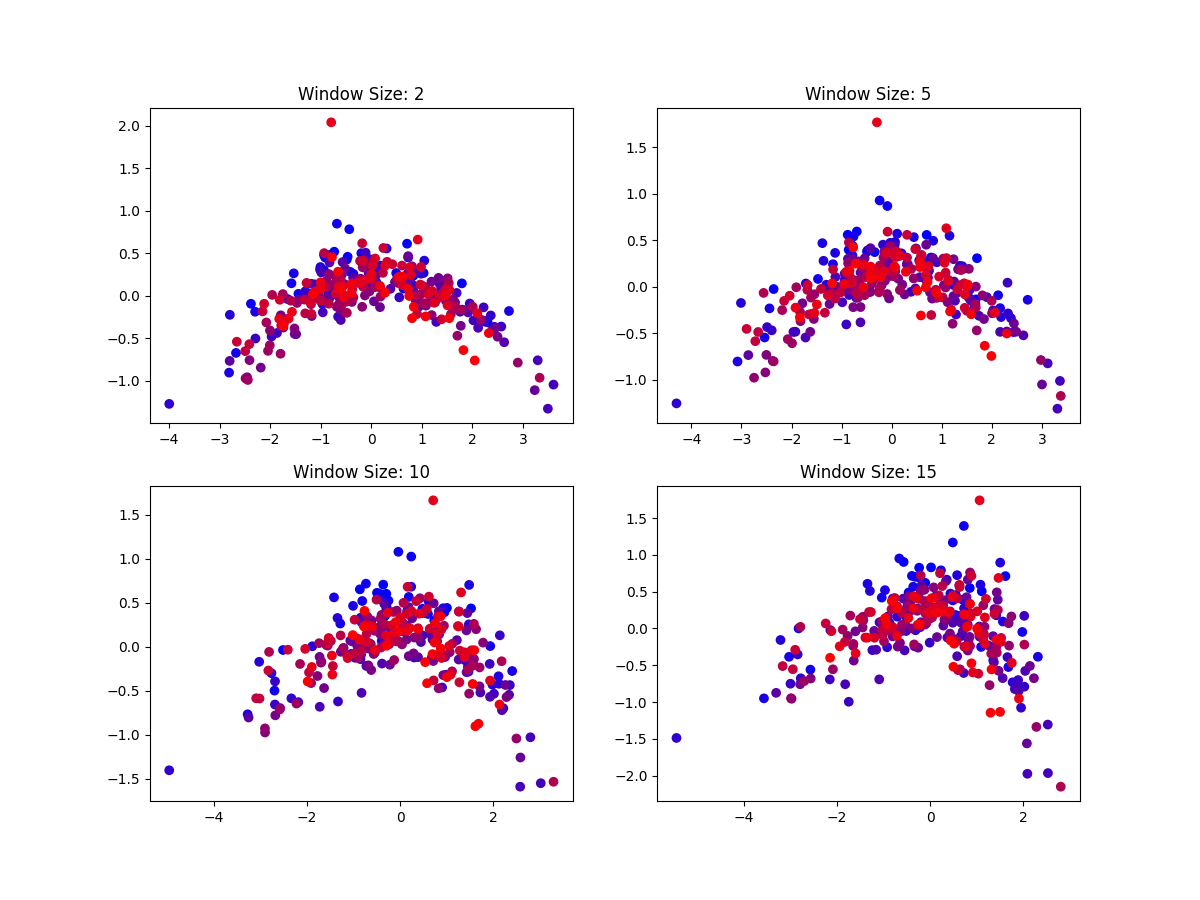
However, vectors trained with both short and long window sizes exhibit the same outlier, suggesting that the difference between this and other chapters is both syntactic and semantic.
Outlier Analysis: Conclusion
While one of the two outliers present in the vector size experiment was easily explainable, attempts at finding the cause of the Tangle 6.4 outlier were inconclusive. As this outlier exists in only the low dimensional representation of the chapters, it is possible that it occurred as a result of an imperfect training process and model, rather than some meaningful difference in the text. Overall, the experiments yielded several possible avenues of further exploration, including examining this outlier in greater detail and looking at how the variation between chapters changes between arcs earlier and later in the text.